
Overview
Owning your own AI is no longer just for tech giants. In 2025, businesses of all sizes are starting to realize the power of hosting their own private GPT model. Why? Because it puts you in control—of your data, your costs, and your future.
1. Your Data Stays Yours
When you call a public API, every prompt and every customer record you send becomes someone else’s liability policy. Hosting the model inside your cloud account or on‑prem server means:
- Zero third‑party retention. Your customer interactions never leave your cloud.
- Easier compliance audits. HIPAA, SOC2, and GDPR audits become far simpler when you control where and how data is stored.
- Fine‑grained access controls. You’re not sending data to third-party platforms they don’t recognize.
Real‑world data point: 70 % of Fortune 500 compliance officers surveyed by IDC in 2024 cited data residency as the #1 blocker to generative‑AI adoption.
2. Predictable Cost at Scale
Most companies hit a tipping point where renting AI becomes more expensive than owning it. Hosting your own model on a rented GPU (like NVIDIA H100) means you pay a flat rate no matter how much you use it.
- At ~300 million tokens/month, the savings start to add up.
- By 450 million tokens, self-hosting can be 80% cheaper than API calls.
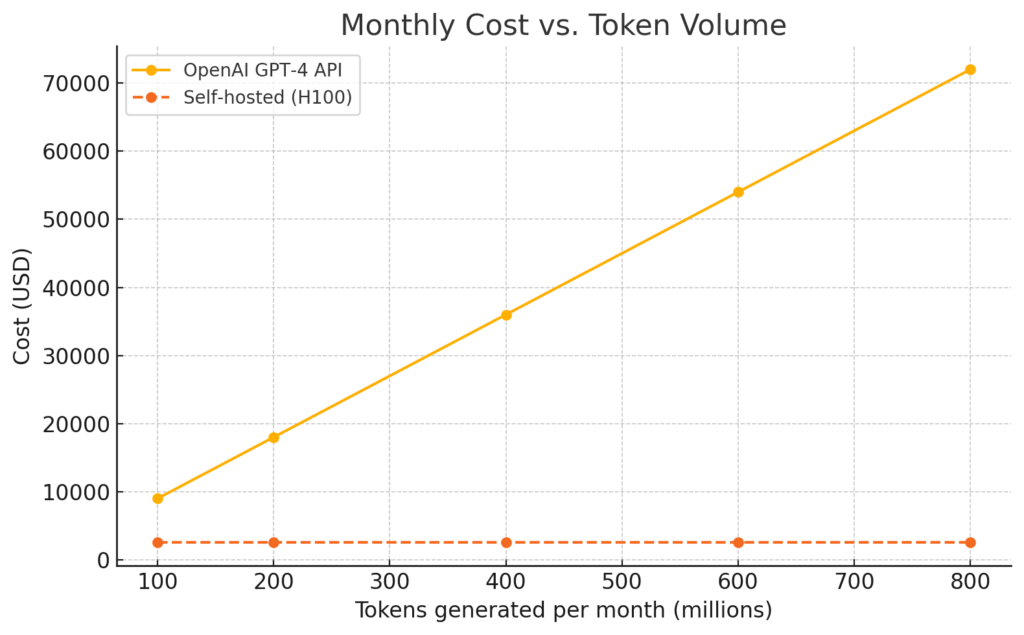
Takeaway: If your app generates more than ~30 million tokens a month, owning the horsepower is already cheaper. At 400 million tokens the API bill explodes past $36k while your server cost is still ~$2.6k.
3. Speed = More Sales
When customers ask a question, delays cost you business. Studies show that reducing AI response time from 800ms to 300ms can increase conversions by 20% or more.
No wait time due to shared API infrastructure.
Hosted models respond faster because they’re close to your product and website.
4. Tailor the Brain to Your Business
Public AI models can’t learn from your unique business knowledge. Hosting your own unlocks:
- Custom fine-tuning on your data.
- Private search pipelines (RAG) that pull answers from your internal docs.
- Guardrails for safe, brand-aligned responses.
You get a model that actually knows your business and talks like your best salesperson.
5. Future-Proof and Flexible
AI tech evolves quickly. Hosting your own model means you can switch to the next best thing (like Mixtral or Llama 3) without being locked into a contract.
- Cloud GPU prices have dropped 27% YoY since 2023.
- Models are getting faster and cheaper to run.
With your own setup, you stay ahead of the curve—no renegotiation needed.
What We Offer
- We help businesses deploy their own private AI stack in under 2 weeks:
- Turnkey setup on AWS, Azure, or your cloud.
- Model selection matched to your needs and budget.
- Security-first design (private endpoints, encrypted data, full audit trail).
- 24/7 monitoring and performance tracking.
Time to first token: 14 days from kick‑off call to production URL.
Ready to Own Your AI Destiny?
Schedule a 30‑minute discovery call and we’ll run a free traffic‑cost simulation using your real usage numbers. Let’s turn LLMs from an experiment into your unfair advantage.

